
Recently I’ve been exploring graph databases and their potential applications. After getting setup with Neo4j, I thought I’d learn how to use the graph query language Cypher and as I’m a bit of a Prog Rock nause decided I would create a knowledge graph based on 1970’s UK and Itallian prog bands.
For those who haven’t come across graph databases before, it’s a database consisting of nodes and relationships and unlike traditional SQL databases, relationships are a main feature of the graph meaning entities are already joined together without the need for traditional SQL joins which can speed up queries when traversing multiple entities.
Three of a Perfect Pair - Creating the Graph
The premise seemed to simple, scrape some data and create a graph DB. However it led me through the murky underworld of RDF query language and another query language SPARQL.
SPARQL allows for a query to consist of triple patterns, conjunctions, disjunctions, and optional patterns - Wikipedia Essentially, SPARQL allows us to query semantically modelled data to return related objects via triples consisting of a subject, a predicate and an object. As an example we could have:
- Subject:Child, Predicate:’has Father’, Object:Father
This works nicely with Neo4j as the triples of subject, predicate, object can easily be loaded as nodes with edges between them as relationships.
Initial Explorations - Wikidata
Wikidata is a “ free and open knowledge base that can be read and edited by both humans and machines.” It also happens to have a very useful query editor which helped me get use to querying using SPARQL. As an example, if I wanted to find all of the albums by The Holy Triumvirate, AKA Rush, the query could look something like:
SELECT DISTINCT ?bandLabel ?albumLabel
WHERE
{
?band wdt:P31 wd:Q5741069 .
?band rdfs:label ?bandName . FILTER REGEX(?bandName,'rush', 'i') .
?album wdt:P175 ?band .
SERVICE wikibase:label { bd:serviceParam wikibase:language "[AUTO_LANGUAGE]". }
}
So what does this mean? I’ll break it down line by line
?band wdt:P31 wd:Q5741069 .
This means assign anything that is an instance of (wdt:P31) a rock band (wd:Q5741069) to the variable ?band.
?band rdfs:label ?bandName . FILTER REGEX(?bandName,'rush', 'i') .
For these values assigned to ?band, assign the band name to ?bandName and filter these by the case insensitive regex expression.
?album wdt:P175 ?band .
SERVICE wikibase:label { bd:serviceParam wikibase:language "[AUTO_LANGUAGE]".
Finally, assign any value that has the performer (wdt:P175) assigned to the ?band variable, which in this case has already been filtered to only contain Rush. The last line is specific to Wikidata and just assigns a variable such as ?bandLabel for each corresponding ?band value in the chosen language.
So there’s a quick example of SPARQL, now let’s get onto building the knowledge graph in Neo4j.
Acquiring the Taste for Graph Databases
I’ve got to acknowledge the blogs of Mark Needham, Adam Cowley and Jesus Barrasa from which I took most of the information for how to build the graph.
Step 0
Don’t make my mistake and skip this step from the n10s docs! This constraint ensures that a URI will be unique across each node in the database.
CREATE CONSTRAINT n10s_unique_uri ON (r:Resource)
ASSERT r.uri IS UNIQUE
Step 1
Running the import procedures would import the data into Neo4j, but without mapping the Wikidata properties to values in the graph it wouldn’t make much sense. By configuring Neosemantics with handleVocabUris set to MAP, you are able to create mappings. This means that when the data is imported into Neo4j it will have more meaning, and no data is lost if/when you choose to export it. https://adamcowley.co.uk/neo4j/importing-wikipedia-data-into-neo4j/
CALL n10s.graphconfig.init({
handleVocabUris: 'MAP'
})
Step 2
Setup prefixes to allow the creation of mappings for the various subject, predicate and object labels.
CALL n10s.nsprefixes.add("bio","http://purl.org/vocab/bio/0.1/");
CALL n10s.nsprefixes.add("vocab","http://dbtune.org/musicbrainz/resource/vocab/");
CALL n10s.nsprefixes.add("foaf","http://xmlns.com/foaf/0.1/");
CALL n10s.nsprefixes.add("sch","http://schema.org/");
CALL n10s.nsprefixes.add("tags","http://www.holygoat.co.uk/owl/redwood/0.1/tags/");
CALL n10s.nsprefixes.add("wd","http://www.wikidata.org/entity/");
CALL n10s.nsprefixes.add("wds","http://www.wikidata.org/entity/statement/");
CALL n10s.nsprefixes.add("wdt","http://www.wikidata.org/prop/direct/");
Step 3
Add the various mappings for the incoming data
CALL n10s.mapping.add('http://www.wikidata.org/prop/direct/P571', 'inception');
CALL n10s.mapping.add('http://www.wikidata.org/prop/direct/P463', 'MEMBER_OF');
CALL n10s.mapping.add('http://www.wikidata.org/prop/direct/P577', 'releaseDate');
CALL n10s.mapping.add('http://www.wikidata.org/prop/direct/P175', 'RELEASED_BY');
Step 4 - Importing the bands
I choose to import the bands from Wikidata as it seemed to have a better way of filtering by country than MusicBrainz, however, for album and member data, MusicBrainz had richer information.
The below is a query to retrieve all British and Italian Prog band which were formed prior to 1980 from Wikidata - this will also retrieve their MusicBrainzID so we can search for them efficiently on MB.
WITH 'PREFIX sch: <http://schema.org/>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
PREFIX wdt: <http://www.wikidata.org/prop/direct/>
PREFIX wd: <http://www.wikidata.org/entity/>
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
CONSTRUCT {
?band a sch:Band ;
sch:name ?bandName ;
wdt:P571 ?startYear ;
wdt:P434 ?mbId .
}
WHERE {
?band wdt:P136 wd:Q49451.
?band wdt:P495 ?country ;
wdt:P571 ?startYear ;
wdt:P434 ?mbId ;
rdfs:label ?bandName . filter (lang(?bandName) = "en") .
FILTER(YEAR(?startYear) <= 1980 && ?country IN ( wd:Q145, wd:Q38 )).
SERVICE wikibase:label { bd:serviceParam wikibase:language "[AUTO_LANGUAGE]". }}'
AS sparql
CALL n10s.rdf.import.fetch(
'https://query.wikidata.org/sparql?query=' + apoc.text.urlencode(sparql),
"JSON-LD",
{ headerParams: { Accept: "application/ld+json"}, handleVocabUris:"MAP" }
)
YIELD terminationStatus, triplesLoaded, triplesParsed
RETURN terminationStatus, triplesLoaded, triplesParsed
I subsequently changed the mapping of P434 with the following query:
MATCH (b:Band)
WHERE b.mbId IS NULL
SET b.mbId = b.P434
REMOVE b.P434;
Step 5 - Add the band members
The next query matches each band, and queries the MusicBrainz SPARQL endpoint to return each member and create the relationship [:MEMBER_OF] for each person’s corresponding band.
MATCH (band:Band)
WITH "
PREFIX sch: <http://schema.org/>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
PREFIX foaf: <http://xmlns.com/foaf/0.1/>
PREFIX mo: <http://purl.org/ontology/mo/>
CONSTRUCT { ?band foaf:member ?memberName }
WHERE { ?band mo:musicbrainz <http://musicbrainz.org/artist/" + band.mbId + "> ;
foaf:member ?members .
?members rdfs:label ?memberName .
}" AS sparql, band
CALL n10s.rdf.stream.fetch(
"http://dbtune.org/musicbrainz/sparql?query=" + apoc.text.urlencode(sparql), 'RDF/XML'
)
YIELD object
WITH band, object as member
MERGE (m:Musician {name: member})
MERGE (m)-[:MEMBER_OF]->(band);
Step 6 - Import the albums and tracks
As the header says, we can now match each Band node and find each bands albums and album tracks from the MusicBrainz endpoint. I’m sure there is a better way to do this but when trying to match on Band nodes using the n10s functions I was returning new duplicate nodes. The workaround was to create a TEMP node with each bands MusicBrainz ID so I could join each band to it’s corresponsing TEMP node, create the relationship between the band and their albums and then delete the temporary nodes.
MATCH (band:Band)
WITH "
PREFIX sch: <http://schema.org/>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
PREFIX foaf: <http://xmlns.com/foaf/0.1/>
PREFIX mo: <http://purl.org/ontology/mo/>
PREFIX dc: <http://purl.org/dc/elements/1.1/>
CONSTRUCT {
?band a sch:TEMP .
?album a sch:Album .
?album sch:releasedBy ?mbId .
?album sch:name ?albumName .
?album sch:releaseDate ?releaseDate .
?album sch:HAS_TRACK ?track .
?track a sch:Track .
?track sch:name ?trackName .
?track sch:trackNumber ?trackNumber .
?track sch:length ?trackLength .
}
WHERE {
?band mo:musicbrainz <http://musicbrainz.org/artist/" + band.mbId + ">;
mo:musicbrainz ?mbId ;
rdfs:label ?bandName .
?album foaf:maker ?band ;
rdf:type mo:Record ;
rdfs:label ?albumName ;
dc:date ?releaseDate ;
mo:track ?track .
?track rdf:type mo:Track ;
rdfs:label ?trackName l
mo:track_number ?trackNumber ;
mo:length ?trackLength .
}" AS sparql, band
CALL n10s.rdf.import.fetch(
"http://dbtune.org/musicbrainz/sparql?query=" + apoc.text.urlencode(sparql), 'RDF/XML'
)
YIELD terminationStatus, triplesLoaded, triplesParsed
RETURN terminationStatus, triplesLoaded, triplesParsed
Create the MusicBrainz ID to match the TEMP nodes.
MATCH (b:Band)
SET b.mbIdString = "http://musicbrainz.org/artist/" + b.mbId
Match the TEMP and BAND nodes on MusicBrainz ID, create the relationships between the band and their albums an then delete the TEMP nodes.
MATCH (r:Resource), (b:Band) WHERE r.uri = b.mbIdString
MATCH (r)<-[:releasedBy]-(a:Album)
MERGE (a)-[:RELEASED_BY]->(b)
DETACH DELETE r
The Power and the Glory (of Neo4J)
So enough with the terrible Prog Rock related headers, here’s a screenshot of the knowledge graph, looking just at the band Gentle Giant
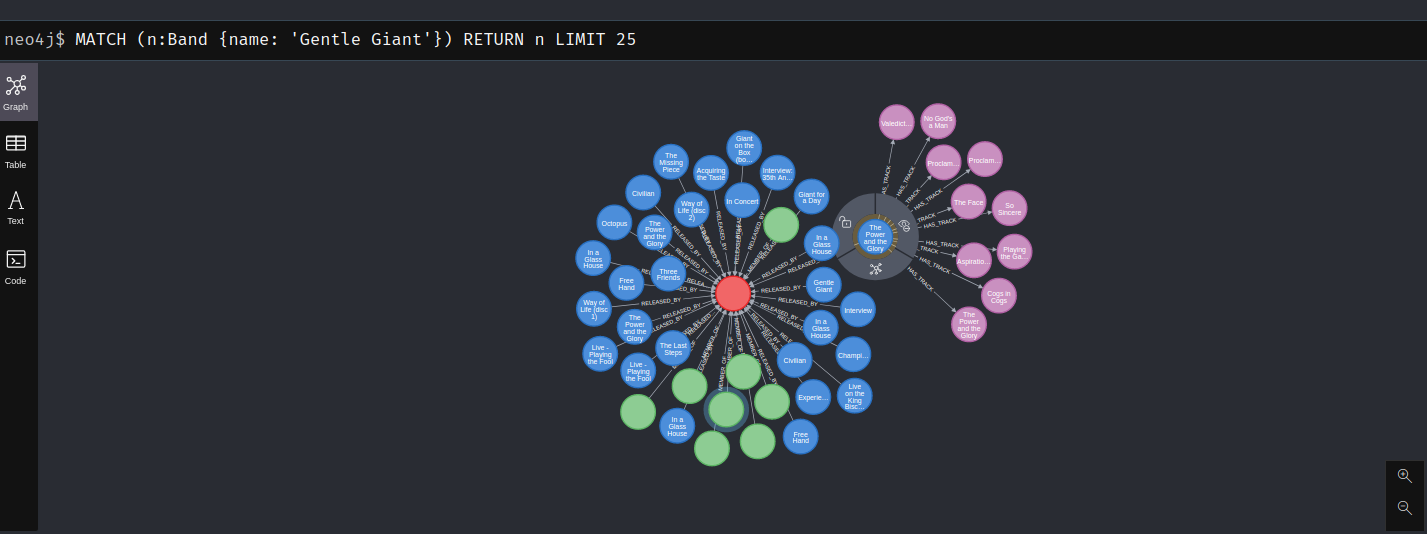
This is just a subset of the data, each album has associated tracks and the musicians can be linked to multiple bands.
Hopefully this has given a brief overview of graph databases. In my next post at look at how we can extract information out of the database using more queries and aggregates. Until then…