
Well, I think it’s only right we start with an apology for the post title. Sorry. However, it will most definitely happen again. So not that sorry I guess.
This week I’ve been exploring GraphQL, a query language for API’s that works incredibly well with graph databases. With GraphQL, we create types that describe our data. A pretty self explanatory example for a person:
type Person {
name: String
age: BigInt
}
We can then query the API for only the information that we want:
query personAge {
person {
age
}
}
And finally receive only the data we have requested:
{
'John Smith': {
age: 36
}
}
So following on from some previous posts on using some Premiership Rugby data, we’ll create a GraphQL API based on the Neo4j database.
Creating Stadia
For the next post, I’ll be looking at how we can incorporate calls to other API’s when querying the GraphQL API. This will need the data about each teams stadium, so this was loaded into the database from a csv.
LOAD CSV WITH HEADERS FROM 'file:///stadiums.csv' AS line
WITH line
WHERE line.stadium IS NOT NULL
CREATE (
s:Stadium {
name: line.stadium,
latitude: line.latitude,
longitude: line.longitude
}
)
WITH line, s
MATCH (t:Team {name: line.team})
CREATE (t)-[:PLAYS_AT]->(s);
Linking each fixture to stadium
The next stage was to link each fixture to the stadium at which it was played. This is where the first problem reared its ugly head. When creating the database, although I’d stored the home team and away team scores, I didn’t load any way to identify which team was the home team and which team was the away team.

To go about this, I had to sum up the points scored by each team in a game from the match event data and then match this to either the home team or away team full time score.
MATCH
(f:Fixture)<-[:APPEARED_IN]-(a:Appearance)-[:IN_SQUAD]->(t:Team),
(p:Player)-[:HAS_APPEARANCE]->(a)
MATCH
(f)-[:HAS_EVENT]->(e)<-[:INDIVIDUAL_EVENT]-(p)
WHERE
(e:Try OR e:`Penalty Try` OR e:Conversion:`Goal Kicked` OR e:`Penalty Goal`:`Goal Kicked` OR e:`Drop Goal`:`Goal Kicked`)
WITH t,f, SUM(
CASE
WHEN e:Try THEN 5
WHEN e:Conversion THEN 2
WHEN e:`Penalty Goal` THEN 3
END
) as groupedScore
MATCH (t)-[rel:TEAM_PLAYED_IN]->(f)
SET rel.home_away =
CASE
WHEN f.HTFTSC = groupedScore THEN 'home'
WHEN f.ATFTSC = groupedScore THEN 'away'
END
The next step was then to simply link the venue to the home team.
MATCH (t:Team)-[rel:TEAM_PLAYED_IN]->(f:Fixture)
WHERE rel.home_away = 'home'
MATCH (t)-[:PLAYS_AT]->(s:Stadium)
MERGE (f)-[:VENUE]->(s)
Starting Simple
When building the GraphQL API, I thought it would be best to use a very simple model to familiarise myself with the language and system. Therefore I took the OPTA match data used in previous posts and simplified it by only keeping the Fixture, Appearance, Team, Player and Referee nodes, thereby eliminating any of the actual match events. However, here came the next issue. It wasn’t as simple as running the following query to eliminate said nodes.
MATCH (n) WHERE n:Stadium OR n:Player or n:Appearance OR n:Team OR n:Fixture
WITH collect(id(n)) as nodeIds
MATCH (d) WHERE NOT id(d) IN nodeIds
DETACH DELETE d
This query didn’t finish and needed a restart of the database to get things running again. If I ran this query again, I would need to increase the heap size in order to make it finish I think. Luckily, APOC has a apoc.periodic.iterate function which allows the process to be ran in batches and in parallel.
CALL apoc.periodic.iterate(
"MATCH (n) WHERE n:Stadium OR n:Player or n:Appearance OR n:Team OR n:Fixture WITH collect(id(n)) as nodeIds MATCH (d) WHERE NOT id(d) IN nodeIds RETURN d",
"DETACH DELETE d",
{batchSize:1000, parallel:true}
)
Some of the deleted nodes may have been connected to each other while this query was running in parallel causing a couple issues on the first run leading to some nodes not being deleted. A second run of the function sorted this out. The alternative would have been to use {batchMode: "BATCH_SINGLE", batchSize: 100} in order to avoid any issues or alternatively save the node ID’s of the nodes to be deleted as a param and pass the list of node ID’s to apoc.nodes.delete.
Introspection
To create the type definitions for the GraphQL API, the Neo4j GraphQL library can automate this by reading the database and creating the schema.graphql file with the @neo4j/introspector package.
To get started, we can store our Neo4j credentials in a .env file
NEO4J_URI=neo4j://localhost:7687
NEO4J_USER=<username>
NEO4J_PASSWORD=<password>
From here, we can then create a file that introspects the database to create the schema file. If you’re not using the default neo4j database name, then don’t forget to pass the database name as an arg to the driver.session function. I lost 15 minutes of my life wondering why there was no schema being generated only to find I was querying an empty database. I refer you to my earlier Elf gif.
The following code was taken mostly from the Neo4j GraphQL docs.
const { toGraphQLTypeDefs } = require("@neo4j/introspector")
const neo4j = require("neo4j-driver");
const fs = require('fs');
const driver = neo4j.driver(
process.env.NEO4J_URI,
neo4j.auth.basic(process.env.NEO4J_USER, process.env.NEO4J_PASSWORD)
);
const sessionFactory = () => driver.session({ defaultAccessMode: neo4j.session.READ, database: "opta-import" }) // don't forget to specify database if it's not the default one
// We create a async function here until "top level await" has landed
// so we can use async/await
async function main() {
const typeDefs = await toGraphQLTypeDefs(sessionFactory)
fs.writeFileSync('schema.graphql', typeDefs)
await driver.close();
}
main()
So what does the output of the introspector look like? The generated schema.graphql is below:
type Appearance {
appearanceId: String!
appearedInFixtures: [Fixture!]! @relationship(type: "APPEARED_IN", direction: OUT)
inSquadTeams: [Team!]! @relationship(type: "IN_SQUAD", direction: OUT)
mins: BigInt!
playersHasAppearance: [Player!]! @relationship(type: "HAS_APPEARANCE", direction: IN)
posId: BigInt!
shirtNumber: BigInt!
}
type Fixture {
ATFTSC: BigInt!
HTFTSC: BigInt!
appearancesAppearedIn: [Appearance!]! @relationship(type: "APPEARED_IN", direction: IN)
fixtureDate: Date!
fxid: BigInt!
teamsTeamPlayedIn: [Team!]! @relationship(type: "TEAM_PLAYED_IN", direction: IN, properties: "TeamPlayedInProperties")
venueStadiums: [Stadium!]! @relationship(type: "VENUE", direction: OUT)
}
type Player {
PLID: BigInt!
forename: String!
hasAppearanceAppearances: [Appearance!]! @relationship(type: "HAS_APPEARANCE", direction: OUT)
surname: String!
}
type Stadium {
fixturesVenue: [Fixture!]! @relationship(type: "VENUE", direction: IN)
latitude: String!
longitude: String!
name: String!
teamsPlaysAt: [Team!]! @relationship(type: "PLAYS_AT", direction: IN)
}
type Team {
appearancesInSquad: [Appearance!]! @relationship(type: "IN_SQUAD", direction: IN)
name: String!
playsAtStadiums: [Stadium!]! @relationship(type: "PLAYS_AT", direction: OUT)
teamId: BigInt!
teamPlayedInFixtures: [Fixture!]! @relationship(type: "TEAM_PLAYED_IN", direction: OUT, properties: "TeamPlayedInProperties")
}
interface TeamPlayedInProperties @relationshipProperties {
home_away: String
}
If we take the Player example, we can see how the GraphQL schema reflects the database schema. We have:
PLID: BigInt!- a non-nullable integer for each playerforename/surname - String!- a none nullable string for each players forename and surnamehasAppearanceAppearances: [Appearance!]! @relationship(type: "HAS_APPEARANCE", direction: OUT)- a non-nullable list of non-nullable appearances for each player, with the relationship and relationship direction specified in the type definition.
The API - Creating an index file
ApolloServer is used to serve the API, and the following file creates the server from the Neo4j database. Again, the following code is pretty much taken from the Neo4j docs.
const { Neo4jGraphQL } = require("@neo4j/graphql");
const { ApolloServer } = require("apollo-server");
const neo4j = require("neo4j-driver");
const fs = require("fs");
const dotenv = require("dotenv");
const path = require("path");
// Load contents of .env as environment variables
dotenv.config();
// Load GraphQL type definitions from schema.graphql file
const typeDefs = fs
.readFileSync(path.join(__dirname, "schema.graphql"))
.toString("utf-8");
// Create executable GraphQL schema from GraphQL type definitions,
// using @neo4j/graphql to autogenerate resolvers
const neoSchema = new Neo4jGraphQL({
typeDefs,
debug: true,
});
// Create Neo4j driver instance
const driver = neo4j.driver(
process.env.NEO4J_URI,
neo4j.auth.basic(process.env.NEO4J_USER, process.env.NEO4J_PASSWORD),
);
// Create ApolloServer instance that will serve GraphQL schema created above
// Inject Neo4j driver instance into the context object, which will be passed
// into each (autogenerated) resolver
const server = new ApolloServer({
context: { driver, driverConfig: { database: "opta-import" }},
schema: neoSchema.schema,
introspection: true,
playground: true
});
// Start ApolloServer
server.listen().then(({ url }) => {
console.log(`GraphQL server ready at ${url}`);
});
All it needs now is to run node index.js and we have a GraphQL API up and running at http://localhost:4000/ which can be accessed in the browser using the Apollo Explorer or via GraphQL Playground.
GraphQL Queries
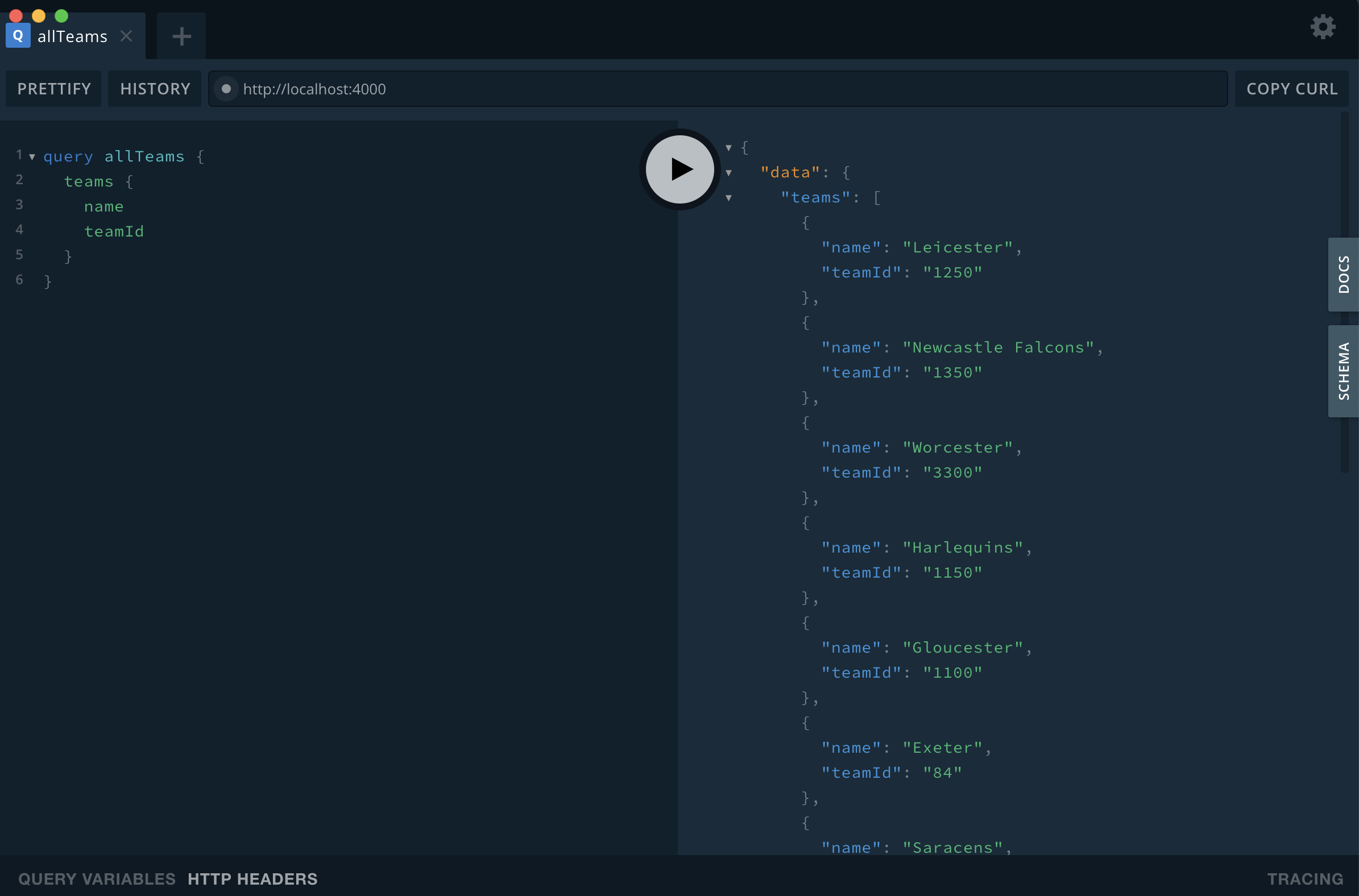
Now we can throw some simple queries at the endpoint. I’ll not go over creating queries in too much detail here (just refer to the GraphQL docs for more details) . But here’s a couple examples. Firstly, a query to return all teams and their respective team ID’s.
query allTeams {
teams {
name
teamId
}
}
// Output
{
"data": {
"teams": [
{
"name": "Leicester",
"teamId": "1250"
},
{
"name": "Newcastle Falcons",
"teamId": "1350"
},
{
"name": "Worcester",
"teamId": "3300"
},
{
"name": "Harlequins",
"teamId": "1150"
},
{
"name": "Gloucester",
"teamId": "1100"
},
{
"name": "Exeter",
"teamId": "84"
},
{
"name": "Saracens",
"teamId": "1500"
},
{
"name": "Northampton",
"teamId": "1400"
},
{
"name": "Wasps",
"teamId": "1550"
},
{
"name": "Sale",
"teamId": "1450"
},
{
"name": "London Irish",
"teamId": "1300"
},
{
"name": "Bath",
"teamId": "1000"
},
{
"name": "Bristol",
"teamId": "1050"
}
]
}
}
And next up, we can take a slightly more complex query. Breaking it down:
- From the list of all teams, take just the team called ‘Leicester’
- Return the team ID
- Find all the fixtures that Leicester played in (this is a relationship in Neo4j) and return the
home_awayproperty from the relationship. - Finally, for all of these fixtures, return the fixture ID (
fxid) and the home and away scores (HTFTSCandATFTSC).
query fixturesByTeam {
teams(where: {name: "Leicester"}) {
teamId
teamPlayedInFixtures {
teamsTeamPlayedInConnection(where: { node: { name: "Leicester"}}) {
edges {
home_away
}
}
fxid
ATFTSC
HTFTSC
}
}
}
// Output
{
"data": {
"teams": [
{
"teamId": "1250",
"teamPlayedInFixtures": [
{
"teamsTeamPlayedInConnection": {
"edges": [
{
"home_away": "away"
}
]
},
"fxid": "120091",
"ATFTSC": "10",
"HTFTSC": "13"
},
...
]
}
]
}
}
Closing Remarks
So there we have it, a simple GraphQL API up and running returning data from a Neo4j database. The next post will look at how we can extend the type definitions in order to include customer Cypher queries.