
Inspired by a recent uneventful stint on jury service, I started wading through the open government datasets just out of curiosity. Maybe I was hoping to unearth the next set of Panama Papers, or maybe there is just alot of waiting around during jury service. Either way, one subset of these datasets piqued my interest: Organograms (which according to Google is just another term for an organization chart).
data.gov.uk has a few of these. They’re available for several government departments and updated once or twice a year - available in csv format or as an interactive hierarchy on the website. So for this week, I thought it would be interesting to see how easy it is to take the csv files and create the organogram in Neo4j.
The Dataset
The data comes spread across two files…the big dogs of the DWP i.e. the senior roles and the junior roles. The first stage is to place these in the import directory of the Neo4j database and then we can get onto the fun stuff.
Loading the data
A quick scan of the data gives us an idea of each field.
head -n 5 DWP\ Organogram\ 31-Mar-2018_0-senior.csv
"Post Unique Reference","Name","Grade (or equivalent)","Job Title","Job/Team Function","Parent Department","Organisation","Unit","Contact Phone","Contact E-mail","Reports to Senior Post","Salary Cost of Reports (£)","FTE","Actual Pay Floor (£)","Actual Pay Ceiling (£)","","Professional/Occupational Group","Notes","Valid?"
"DWP601","N/D","SCS1","CM CSA director","The CSA Director is responsible for: CSA case maintenance and transitioning cases to CM 2012. -","Department for Work and Pensions","Department for Work and Pensions","Operations - Child Maintenance Group","020 7449 7720","correspondence@dwp.gsi.gov.uk","DWP231","15284730","1.00","65000","69999","","Operational Delivery","","1"
So we have unique post references which is suggesting these could be used as an index for each post. There are also a few properties about each role and then departments, organisations and units that each role belongs to so these should be modelled as separate nodes instead of being properties.
The first query creates a uniqueness constraint on a Post node ensuring each post reference is unique. Next, each role is created as a node and assigned various properties. Finally, the query creates any organisations, departments and units and finally creates the relationship between each role and each org, dept and unit.
CREATE CONSTRAINT UniqueRoleId ON (n:Post) ASSERT n.postRef IS UNIQUE;
LOAD CSV WITH HEADERS FROM 'file:///dwp_senior.csv' AS row
WITH row WHERE row.`Post Unique Reference` IS NOT NULL
MERGE (p:Post {postRef: row.`Post Unique Reference`})
ON CREATE SET
p.jobFunc = row.`Job/Team Function`,
p.payFloor = row.`Actual Pay Floor (£)`,
p.contactEmail = row.`Contact E-mail`,
p.contactPhone = row.`Contact Phone`,
p.valid = row.`Valid?`,
p.jobTitle = row.`Job Title`,
p.name = row.Name,
p.reportsSalary = row.`Salary Cost of Reports (£)`,
p.fte = row.FTE,
p.grade = row.`Grade (or equivalent)`,
p.payCeiling = row.`Actual Pay Ceiling (£)`,
p.notes = row.`Notes`
MERGE (o:Organisation {name: row.Organisation})
MERGE (p)-[:PART_OF_ORG]->(o)
MERGE (u:Unit {name: row.Unit})
MERGE (p)-[:FROM_UNIT]->(u)
MERGE (pg:ProfessionalGroup {name: row.`Professional/Occupational Group`})
MERGE (p)-[:FROM_PROF_GROUP]->(pg)
It would be difficult to assign any REPORTS_TO relationships on the first pass of the data as there is no guarantee that the node of who a person reports to will have been created when creating the person. Therefore on a second pass of the data, we can assign all REPORTS_TO relationships.
LOAD CSV WITH HEADERS FROM 'file:///dwp_senior.csv' AS row
WITH row WHERE row.`Post Unique Reference` IS NOT NULL
MATCH (p:Post {postRef: row.`Post Unique Reference`})
MATCH (s:Post {postRef: row.`Reports to Senior Post`})
MERGE (p)-[:REPORTS_TO]->(s)
Loading the junior roles
The senior roles were easy to load as each role had a unique reference. The junior roles were slightly more difficult as not only did each post not have a unique reference or unique combination of properties, but each role also contained a FTE (full time equivalent) value, meaning we would need to create multiple nodes for each row equating to the number of FTE roles.
For this we would need to use Cypher’s FOREACH function and iterate through the number of FTE roles.
LOAD CSV WITH HEADERS FROM 'file:///dwp_junior.csv' AS row
WITH
row,
// convert the fte value to an integer value
toInteger(CEIL(toFloat(row.`Number of Posts in FTE`))) as numFTE
WHERE row.`Generic Job Title` IS NOT NULL
MATCH (p:Post {postRef: row.`Reporting Senior Post`})
MATCH (o:Organisation {name: row.Organisation})
MATCH (u:Unit {name: row.Unit})
MATCH (pg:ProfessionalGroup {name: row.`Professional/Occupational Group`})
// Iterate through each value in the range 1 through to the num
// of FTE roles
FOREACH (
i in range(1, numFTE+1) |
// For each i, create a new post with the given attributes
CREATE
(j:juniorPost {
jobTitle: row.`Generic Job Title`,
jobId: i,
payCeiling: row.`Payscale Maximum (£)`,
grade: row.Grade,
payFloor: row.`Payscale Minimum (£)`
}
)
CREATE (j)-[:PART_OF_ORG]->(o)
CREATE (j)-[:FROM_UNIT]->(u)
CREATE (j)-[:FROM_PROF_GROUP]->(pg)
CREATE (j)-[:REPORTS_TO]->(p)
)
Eagle eyed reaeders will also notice the use of CREATE over MERGE in this instance. This is because there was no unique combination of properties for many of the junior nodes meaning certain nodes weren’t being created as expected.
Querying the data
Let’s run a few queries on the new database.
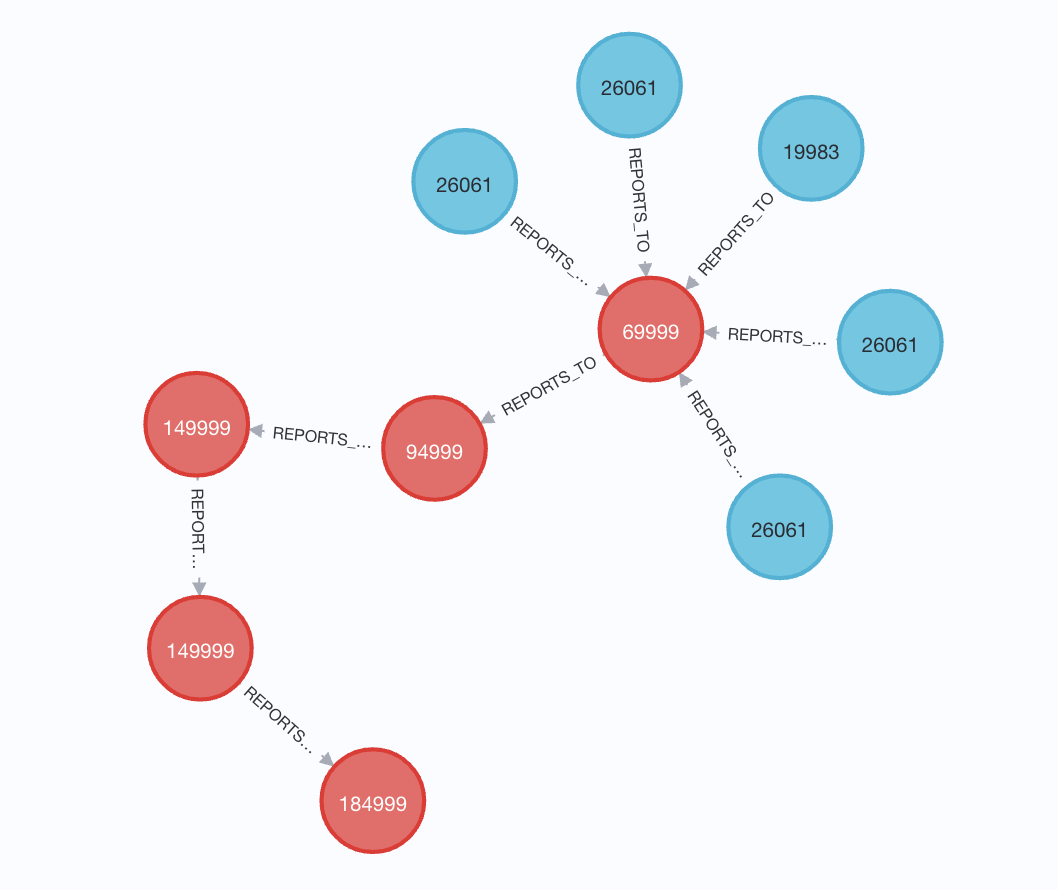
Firstly, what is the longest reporting chain?
// Match a person who has people report to them
MATCH (person)
WHERE EXISTS (()-[:REPORTS_TO]->(person))
AND NOT EXISTS ((person)-[:REPORTS_TO]->())
// Find a path from people at the bottom ladder all the way to the top
MATCH path=(sub)-[:REPORTS_TO*]->(person)
WHERE NOT EXISTS(()-[:REPORTS_TO]->(sub))
WITH path, size(nodes(path)) as lenPath ORDER BY lenPath DESC LIMIT 5
RETURN path, lenPath
And from here we can see the path from the bottom to the top and the pay ceiling for each level. Lovely stuff.
Next, can we calculate the sum of all the salaries for each persons reporting chain? Yes, yes we can. Although we need to be careful we don’t return duplicate nodes when matching reporting paths.
// Variable length pattern match
MATCH path=(n)<-[:REPORTS_TO*1..]-(sub)
// Take the highest person in the chain and all other as a separate array
WITH n, [p in nodes(path) WHERE id(p) <> id(n)] as people
UNWIND people as p
// The above will return mulitple paths, so unwind and collect only the
// distinct nodes
WITH n.postRef as postRef, collect(distinct p) as subs
UNWIND subs as sub
RETURN postRef, SUM(toInteger(sub.payCeiling)) as sumOfSalaries
ORDER BY sumOfSalaries DESC LIMIT 10;
╒═════════╤═══════════════╕
│"postRef"│"sumOfSalaries"│
╞═════════╪═══════════════╡
│"DWP135" │2061678525 │
├─────────┼───────────────┤
│"DWP202" │1681214658 │
├─────────┼───────────────┤
│"DWP448" │778461285 │
├─────────┼───────────────┤
│"DWP503" │315839408 │
├─────────┼───────────────┤
│"DWP343" │217128086 │
├─────────┼───────────────┤
│"DWP379" │205511896 │
├─────────┼───────────────┤
│"DWP43" │169389013 │
├─────────┼───────────────┤
│"DWP249" │158615675 │
├─────────┼───────────────┤
│"DWP512" │148309144 │
├─────────┼───────────────┤
│"DWP60" │145847174 │
└─────────┴───────────────┘
And there we have it, the sum of salaries for each reporting line. A quick sanity check shows that these roughly match up with the property of a Post node called reportingSalary so we’ll take that as a win for the query!
I’m tempted to take all the organagrams for every department available on the government data website and build one huge graph with every post in there. Maybe one for next week…